ストックマーク独自開発LLMが国内オープンモデルの中でも最高性能を記録 日本語特化の1,000億パラメータLLM「Stockmark-2-100B-Instruct-beta」を公開
~日本語領域・ビジネスドメインの両面で最高スコアを記録~
ストックマーク株式会社(本社:東京都港区、社長:林 達、以下:当社)は、経済産業省とNEDOが実施する国内の生成AI開発力強化を目的としたプロジェクト「GENIAC」第2期にて、日本語を主な対象とした1,000億パラメータの大規模言語モデル (Large Language Model、以下:LLM)を開発しております。
この度、開発中のLLMにて、国内組織によってフロムスクラッチ※1で開発されたオープンモデルと比較しても、一定の差をもって高い性能を発揮することが確認できたため、現段階のモデル「Stockmark-2-100B-Instruct-beta」をベータ版として公開をいたしました。また、当モデルの開発は現在も続いており、更なる精度向上に努めてまいります。
※1:システムを作る際に、既存のモデルを用いずに組み上げる開発手法
【Stockmark-2-100B-Instruct-beta公開先】
https://huggingface.co/stockmark/Stockmark-2-100B-Instruct-beta
「Stockmark-2-100B-Instruct-beta」について

この度公開した「Stockmark-2-100B-Instruct-beta」は、日本語を主な対象として学習された1,000億パラメータの日本語特化型LLMです。その特徴として、公開されている既存のLLMモデルを用いずに、当社がゼロから開発を行った独自モデルとなっております。
当社では、2024年5月にハルシネーション※2大幅に抑止した1,000億パラメータのLLM「Stockmark-LLM-100b※3」を独自開発・公開をしております。「Stockmark-LLM-100b」の開発を通して得た知見や課題を活かすことで、今回の「Stockmark-2-100B-Instruct-beta」の開発・公開に至りました。
なお、「Stockmark-LLM-100b」の特徴である、ハルシネーションの大幅抑止・厳密性が重要視されるビジネスドメインにおける高い回答性能は踏襲しているため、高い日本語能力と深いビジネス知識を併せ持った、ビジネスドメインで信頼して活用いただけるモデルとなっております。
また、「Stockmark-2-100B-Instruct-beta」は、商用利用可能なモデルとしてオープンソースで公開することで、より多くのユーザーにお試しいただくことできるモデルとなっています。
・Stockmark-LLM:https://llm.stockmark.co.jp
※2:人工知能が学習したデータからは正当化できないはずの回答を堂々とする現象
※3: https://stockmark.co.jp/news/20240516
「Stockmark-2-100B-Instruct-beta」開発の背景
「Stockmark-2-100B-Instruct-beta」は、経済産業省とNEDOが実施する、国内の生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて開発されたものです。GENIACでは、国内事業者に対して生成AIの開発に必要な計算資源の確保と利用料補助が実施されます。なお、当社は2024年2月の第1期※4、同年10月の第2期※5の双方で採択されております。
第1期においては、厳密さが要求されるビジネスドメインにおいて信頼可能な、ハルシネーションを大幅に抑止した1,000億パラメータの「Stockmark-LLM-100b」を開発しました。
第2期においては、「ハルシネーションを抑止したドキュメント読解基盤モデルの構築」をテーマに、企業の業務で頻繁に扱われる複雑なドキュメントを、正確に理解可能なマルチモーダル※6の基盤モデルの開発を行なっております。事業としては大別して、以下の2つのパートで構成されております。
(1)基盤となる日本語性能の高い1,000億パラメータのLLMをフルスクラッチで開発
(2)上記にて開発したLLMに対してマルチモーダル学習を行い、
複雑なビジネスドキュメント高い正確性をもって読解可能なマルチモーダルLLMの開発
この度、公開した「Stockmark-2-100B-Instruct-beta」は(1)に該当するモデルであり、今後当モデルの更なる精緻化に努めるとともに、(2)のパートであるドキュメント読解LLMの開発を進めてまいります。
また、当社は産業技術総合研究所とLLMに関する共同研究をおこなっており、今回のプロジェクトの遂行にあたっても助言をいただきました。
※4:https://stockmark.co.jp/news/20240202
※5:https://stockmark.co.jp/news/20241010
※6:テキスト・音声・画像・動画など、複数の種類のデータを一度に処理可能な深層学習の一種
性能評価
「Stockmark-2-100B-Instruct-beta」の性能評価は、日本語MT-Benchによって既存モデルと評価を実施しました。今回の評価では、日本の組織によってフロムスクラッチで開発が行われた公開モデルと性能を比較したところ、一定の差を持って高い性能を示していることがわかりました。
また、Meta社が開発したLlama3.1に日本語を追加学習した「Llama 3.1 Swallow」と比較しても、今回開発した「Stockmark-2-100B-Instruct-beta」が僅かに上回る結果となりました。
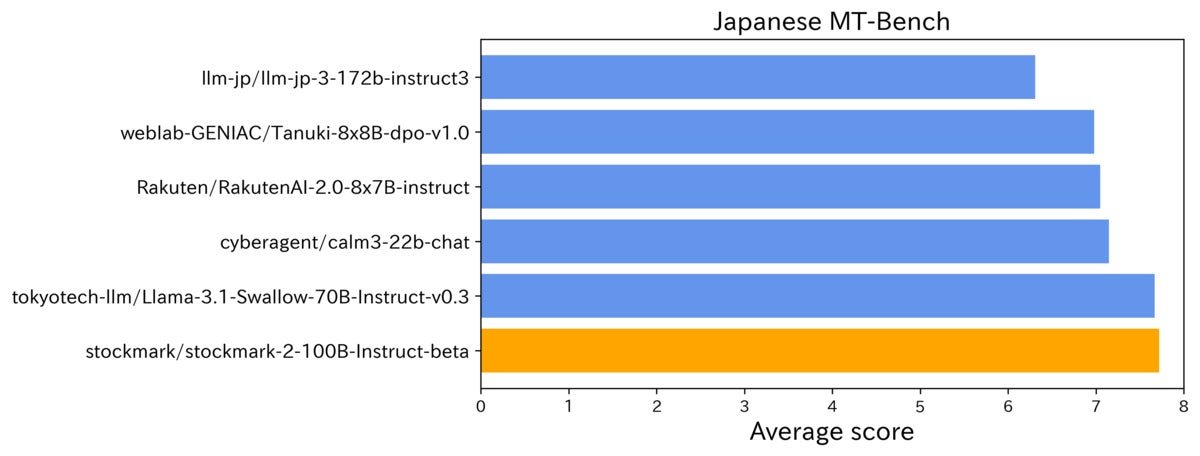
更に、今回日本語に特化したモデルを開発するにあたり、日本のビジネスドメインにおける知識の保持度を評価しました。評価には、当社が開発したStockmark Business Questions※7を用いた結果、本モデルの正解率は 90% となり、GPT-4o の正解率(88%)をわずかに上回る ことが確認されました。
※7:https://huggingface.co/datasets/stockmark/business-questions
GENIACについて

「GENIAC」は、経済産業省とNEDOが実施する、日本国内の基盤モデル開発力を底上げし、また企業等の創意工夫を促すためのプロジェクトです。
計算資源の提供、利活用企業やデータホルダーとのマッチング支援、 グローバルテック企業との連携支援やコミュニティイベントの開催、 開発される基盤モデルの性能評価など、生成AIによって世界の変革がもたらされようとしている中、国内外の関係者の知見を結集し、日本の開発力向上を目指します。
ストックマーク株式会社について
ストックマーク株式会社は「価値創造の仕組みを再発明し、人類を前進させる」をミッションに掲げ、最先端の生成AI技術を活用し、多くの企業の企業変革を支援しています。
社内外の情報をワンストップで検索できる「Anews」及び、あらゆるデータを構造化し企業の資産に変える「SAT(Stockmark A Technology)」を運営しています。さらに、企業特化生成AIの開発や、独自システムの構築も支援しています。
会社名 :ストックマーク株式会社
所在地 :東京都港区南青山一丁目12番3号 LIFORK MINAMI AOYAMA S209
設立 :2016年11月15日
代表者 :代表取締役CEO 林 達
事業内容:自然言語処理を活用した、
事業機会の探索と意思決定の支援を行うサービスの開発・運営
URL :https://stockmark.co.jp/
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- システム・Webサイト・アプリ開発アプリケーション・セキュリティ
- ダウンロード
